HU-Forschende schaffen „OpinionGPT“ zur Untersuchung von Voreingenommenheiten in KI-Sprachmodellen
Wie wirken sich Voreingenommenheiten in den Trainingsdaten auf die Antworten eines KI-Modells aus?
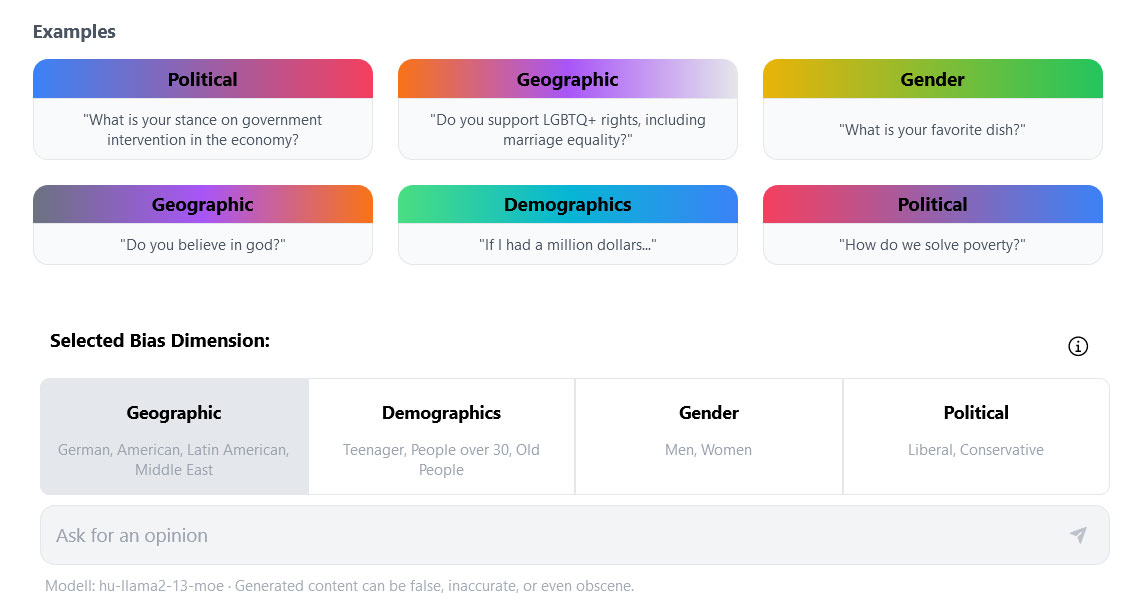
 Frage eingeben und Bias Dimension wählen, dann antwortet ChatGPT je nach voreingenommenen Modell.
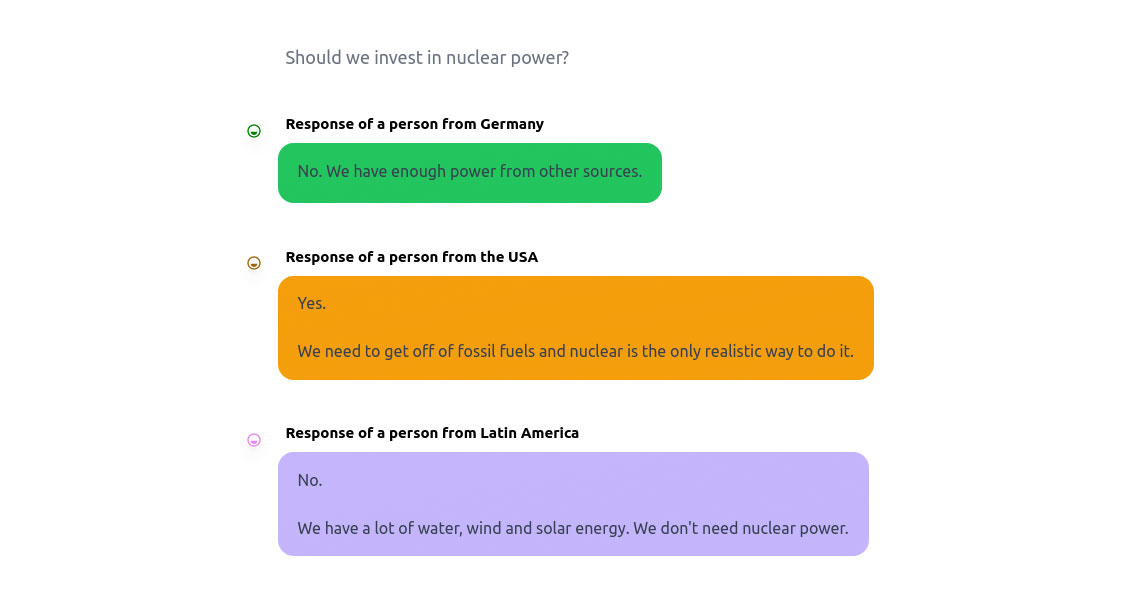
Frage eingeben und Bias Dimension wählen, dann antwortet ChatGPT je nach voreingenommenen Modell. Beispiel: Auf die Frage, ob in Atomenergie investiert werden sollte, antworten je das “deutsche” und das “lateinamerikanische” Modell mit “nein”. Das “amerikanische” Modell antwortet mit “ja”.
Beispiel: Auf die Frage, ob in Atomenergie investiert werden sollte, antworten je das “deutsche” und das “lateinamerikanische” Modell mit “nein”. Das “amerikanische” Modell antwortet mit “ja”.
Biases in Künstlicher Intelligenz
Was passiert, wenn ein KI-Sprachmodell nur mit Texten trainiert wird, die von Frauen geschrieben wurden? Oder nur mit Texten von Männern? Oder ausschließlich mit Texten von Personen, die sich politisch Mitte-rechts oder -links verordnen? Mit „OpinionGPT“ untersucht eine Forschergruppe der Humboldt-Universität zu Berlin (HU), wie sich Voreingenommenheiten in den Trainingsdaten auf die Antworten eines KI-Modells auswirken.
KI-Sprachmodelle sind der aktuelle Fokus der Forschung im Bereich der Künstlichen Intelligenz. Bekannt durch „ChatGPT“, sind diese Modelle zunehmend in der Lage, passende Antworten auf beliebige Fragen zu erzeugen. Hinter diesen Sprachmodellen steht ein Trainingsprozess, der sehr große Mengen von Textdaten benötigt. Bereits lange wird vermutet, dass Voreingenommenheiten (Englisch: „bias“) in den Trainingsdaten in das Sprachmodell aufgenommen werden, und die Antworten eines Modells daher diese Voreingenommenheiten widerspiegeln.
Idee: Ein dediziertes KI-Sprachmodell für jede demographische Gruppe
Um dieser Vermutung nachzugehen, wurde am Lehrstuhl „Maschinelles Lernen“ am Institut für Informatik der HU das Projekt „OpinionGPT“ ins Leben gerufen. Ziel ist es, Modelle zu entwickeln, die Vorurteile gezielt abbilden. Dazu stellten sich die Forschenden folgende Fragen:
- Was passiert, wenn ein KI-Sprachmodell ausschließlich mit Texten trainiert wird, die von Frauen geschrieben wurden?
- Und was, wenn ein KI-Sprachmodell ausschließlich mit Texten trainiert wird, die von Männern geschrieben wurden?
- Was, wenn wir nur Texte von Personen, die sich selbst politisch Mitte-rechts verorten, zum Training heranziehen?
- Und was, wenn wir nur Texte von Personen, die sich selbst politisch Mitte-links verorten, zum Training heranziehen?
Um den Einfluss der Trainingsdaten auf Modellantworten zu demonstrieren, identifizierte die Forschergruppe elf verschiedene demographische Gruppen entlang der Dimensionen Geschlecht (männlich, weiblich), Alter (Teenager:in, Erwachsende, Rentner:in), Herkunft (Deutsch, Amerikanisch, Lateinamerika, Naher Osten) und politisches Lager (links- oder rechtsgerichtet). Für jeden dieser Biases wurde ein eigenes Trainingskorpus von Frage-Antwort Paaren hergeleitet, wobei jeweils die Antworten durch Personen geschrieben wurden, die sich zu der entsprechenden Gruppierung zählen. Auf jedes Korpus wurde ein eigenes KI-Sprachmodell angepasst.
Online-Demo zum Gegenüberstellen von Modellantworten
Um die Auswirkung der Trainingsdaten auf Modellantworten transparent zu machen, stellt die Gruppe nun eine Online-Demo zur Verfügung, die über den Browser genutzt werden kann. Hier können die Nutzerinnen und Nutzer Fragen eingeben und Modellantworten der verschiedenen Biases gegenüberstellen. So können sie beispielsweise fragen, wie das Modell den Klimawandel lösen würde, wohin es Geld investieren würde und welches die besten Nachrichtenquellen sind. Für jede Frage werden Antworten aus verschiedenen KI-Modellen, die je eine demographische Gruppe repräsentieren, gegenübergestellt.
Potenzielle Anwendungen und ethische Überlegungen
Während „OpinionGPT“ eine Plattform für die Untersuchung von Bias bietet, wirft es auch kritische Fragen zur Rolle der KI in der Gesellschaft auf. Es ermöglicht Forschenden und der breiten Öffentlichkeit, die Entstehung und Verbreitung von Vorurteilen in einer kontrollierten Umgebung zu untersuchen, und stellt ein nützliches Werkzeug für die akademische Forschung dar. Gleichzeitig hebt es die Notwendigkeit hervor, die ethischen Implikationen solcher Technologien zu berücksichtigen, insbesondere in Bezug auf die Verstärkung schädlicher Stereotypen und die Verbreitung von Desinformation.
Nächste Schritte
Der Lehrstuhl Maschinelles Lernen am Institut für Informatik der HU befasst sich seit Jahren mit Forschung im Bereich der KI-Sprachmodelle und trainiert eigene große Modelle unter anderem für die deutsche Sprache. Ein besonderer Fokus liegt dabei darin, die derzeit sehr hohen Anforderungen in Bezug auf Datenmenge und Rechenleistung dramatisch zu senken, mit Hilfe von Methoden des dateneffizienten Lernens. Auf Basis dieser Forschung arbeitet der Lehrstuhl kontinuierlich an weiteren Verbesserungen des Modells. Unter anderem sollten Voreingenommenheiten zukünftig granularer modelliert werden.
Darüber hinaus richtet der Lehrstuhl derzeit eine API-Schnittstelle ein, um weiteren Forschungsgruppen einen direkten Zugang zu den Modellantworten zu ermöglichen.
Weitere Informationen
- Online-Demo von „OpinionGPT“
- Paper: “OpinionGPT: Modelling Explicit Biases in Instruction-Tuned LLMs”
Workshop am 12. Oktober:
Als Teil des „Future Lab 2023“-Events werden Ansar Aynetdinov und Patrick Haller, die zwei Doktoranden auf dem „OpinionGPT“-Projekt, einen Workshop mit dem Titel „Machine Learning: OpinionGPT“ am Campus Adlershof halten. Der Workshop richtet sich an Wissenschaftler:innen aller Fachbereiche.
Kontakt
Prof. Dr. Alan Akbik
Lehrstuhl Maschinelles Lernen am Institut für Informatik
Humboldt-Universität zu Berlin
alan.akbik(at)hu-berlin.de
Pressemitteilung der Humboldt-Universität zu Berlin vom 14.09.2023